
1、题目名称
Rank Scores(按分数排名次)
2、题目地址
3、题目内容
按分数排名次,如果两个Id的分数一样,那么他们的名次是一样的,排名从1开始。注意,每组分数的名次,都是上一组分数名次加一。
例如,表Scores中有这样一组数据:
+----+-------+| Id | Score |+----+-------+| 1 | 3.50 || 2 | 3.65 || 3 | 4.00 || 4 | 3.85 || 5 | 4.00 || 6 | 3.65 |+----+-------+
排名后输出的数据应该为:
+-------+------+| Score | Rank |+-------+------+| 4.00 | 1 || 4.00 | 1 || 3.85 | 2 || 3.65 | 3 || 3.65 | 3 || 3.50 | 4 |+-------+------+
4、初始化数据库脚本
在MySQL数据库中建立一个名为LEETCODE的数据库,用MySQL命令行中的source命令执行下面脚本:
-- 执行脚本前必须建立名为LEETCODE的DATABASEUSE LEETCODE; DROP TABLE IF EXISTS Scores;CREATE TABLE Scores ( Id INT NOT NULL PRIMARY KEY, Score FLOAT); INSERT INTO Scores (Id, Score) VALUES (1, 3.50);INSERT INTO Scores (Id, Score) VALUES (2, 3.65);INSERT INTO Scores (Id, Score) VALUES (3, 4.00);INSERT INTO Scores (Id, Score) VALUES (4, 3.85);INSERT INTO Scores (Id, Score) VALUES (5, 4.00);INSERT INTO Scores (Id, Score) VALUES (6, 3.65);
5、先参考以下另外两种排名方法
排名的方式有很多种,抛开这道题目来说,常见的排名方式有两种:
第一种排名方式,是直接按分数对成员进行排列,名次从1开始依次递增,当两个人分数相同时,也要按出现的先后顺序或其他规律分出先后。这样排序的SQL语句如下:
SELECT Score, @Counter := @Counter + 1 AS RankFROM Scores, (SELECT @Counter := 0) AS CORDER BY Score DESC;
排序后的截图如下:
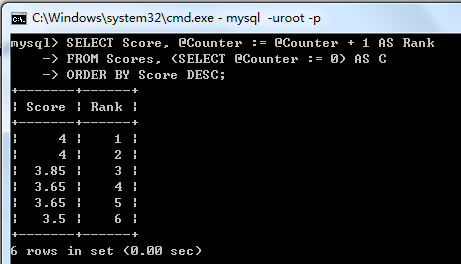
(这个SQL同时也适用于给某一组查询结果添加行号)
第二种排名方式,是按分数对成员排列,如果两个Id分数相同,则名次相同,但不影响排名靠后人的名次。例如某比赛两个人并列第一,那么这个比赛就不再有第二名,得分第二高的人会被算作第三名。这样排序的SQL语句如下:
SELECT S1.Score, ( SELECT COUNT(Score) + 1 FROM Scores S2 WHERE S1.Score < S2.Score) AS RankFROM Scores S1ORDER BY S1.Score DESC;
排序后的截图如下:

6、解题SQL
我想出的方法是用DISTINCT关键字,先排出分数(Score)的名次保存在一个临时结果集中,在跨原表和这个临时结果集匹配出各个Id对应的名次。一个实现此思路的SQL语句为:
SELECT A.Score, B.RankFROM Scores AS A, ( SELECT Score, @Counter := @Counter + 1 AS Rank FROM (SELECT DISTINCT Score FROM Scores) AS DIS_S, (SELECT @Counter := 0) AS C ORDER BY Score DESC) AS BWHERE A.Score = B.ScoreORDER BY A.Score DESC;
查询结果截图如下:

7、其他解题SQL
后来我又查看了以下原题目的Dicuss板块,里面有很多不同的SQL语句实现这个功能,尤其是这个帖子:
现将几个SQL和相关思路整理后列在下面
1)使用两个变量rank和prev存储当前的名次和前一个名次的分数,分数变化时,名次加一
SELECT Score, @rank := @rank + (@prev <> (@prev := Score)) RankFROM Scores, (SELECT @rank := 0, @prev := -1) InitORDER BY Score DESC;
2)每个Id的Rank值,是得分小于该Id的数据行数
SELECT Score, ( SELECT COUNT(DISTINCT Score) FROM Scores WHERE Score >= s.Score) RankFROM Scores sORDER BY Score DESC;
3)和前一个方法类似
SELECT Score, ( SELECT COUNT(*) FROM ( SELECT DISTINCT Score S FROM Scores) AS Tmp WHERE S >= Score) AS RankFROM ScoresORDER BY Score DESC;
4)下面这个方法,也是选出比当前Id得分高的得分的个数,作为当前Id对应的名次
SELECT S.Score, COUNT(DISTINCT T.Score) AS RankFROM Scores S JOIN Scores T ON S.Score <= T.ScoreGROUP BY S.IdORDER BY S.Score DESC
END